
Last Updated on January 27, 2025 by Cass Rosas
You and your team could be getting much more out of your data.
The purpose of data, after all, is to make better business decisions through the reduction of uncertainty.
But data has tons of limitations, and by itself has no inherent value. You need a human to interpret the data and determine a course of action.
What is Data Literacy?
Data literacy is such a simple concept: it’s being literate when it comes to reading, understanding, creating, and analyzing data. Basically, it means you know how to work with data well.
Again, data by itself isn’t valuable. A real life human with data skills needs to work with it to make better decisions.
It’s not just for data scientists or a chief data officer (cdo). Every decision maker and anyone working with data (isn’t that everyone nowadays?!) should be data literate.
Your specific data literacy index could vary depending on the needs of the job. So data literacy training could include concepts like data analytics (understanding the tool itself or the underlying data structures), data visualizations, business intelligence tools, advanced data science, or perhaps just understanding the language of data to communicate with business leaders.
There are tons of pitfalls in the process of using and understanding data. Reduce your frustrations and data malpractices, and increase your data literacy skills, with the following less known and underrated concepts.
- Understand database querying and their underlying infrastructure
- Know and understand different data types
- The Utility vs. Precision trade-off
- Bias vs. Variance
- Signal vs. Noise
- Correlation vs. Causation
- Correlation vs. Correlation
- Narrative Fallacies and Common Biases
- Twyman’s Law
- Leaky Abstractions in Analytics Tools
1. Understand database querying and underlying infrastructure
Understanding basic database architecture and querying (SQL) concepts will help you universally, no matter which specific analytics tool you’re using at your company.
First off, if your company is of a certain size, this should be managed by a specific team through data cataloging. It shouldn’t be, though it often is, a multi-day search to find basic data tables in some organizations.
Also, databases aren’t scary (nor is SQL, the common database querying language). If you’ve worked in spreadsheets, you already understand many of the basic concepts. A VLOOKUP in Excel is kind of like a JOIN in SQL. A Pivot Table lets you GROUP BY different variables. Filters are like a WHERE function in SQL. Formulas of course let you SUM, COUNT, etc. — all of which you can do with SQL as well.

To start, take a quick SQL course. There are free ones online from Udacity and Codecademy, or you can do a quick day course at General Assembly or something. Helps to learn the syntax and get some practice, but eventually you’ll want to query real life databases.
I find theory and practice datasets can hit quick diminishing returns, and eventually you’ve gotta play with some skin in the game.
Beyond databases and generic SQL knowledge, I recommend taking a course or reading the documentation on your analytics tool of choice. If your organization uses Adobe Analytics, it would help to really understand how that data is collected and surfaced. I dove deep in Google Analytics and it has helped me a bunch at HubSpot (and now with agency clients as well).
Knowing the differences in Google Analytics Scopes will let you understand, for example, why your “All Pages” report in Google Analytics (hit-scoped) doesn’t show conversion rates (which are session-scoped).
Knowing the difference in how a user, session, hit, etc. are calculated matters a lot for how you interpret that data. Best GA course to take is from CXL Institute, hands down.
2. Know Different Data Types
Knowing how data is stored is great, but even better is to grok the core underlying data types.
At a high level, data types branch off into either:
- Categorical data
- Numerical data
Categorical data represents characteristics. They can also be represented numerically (think 1 for a dog and 0 for a cat, or something like that).
Categorical data splits off into two more branches:
- Nominal
- Ordinal
Nominal data are discrete variables that don’t have quantitative value (“which college did you attend” would create nominal categorical data)
Ordinal data represents discrete and ordered units (same thing as nominal, but order matters — think “education level” and values like “high school,” “bachelor’s,” “master’s” etc)

Numerical data can be discrete (conversion rate, or number of heads in 100 coin flips) or continuous variables (things like height or temperature — these can be further broken up into ratio or interval variables). The difference here can be confusing so here’s a post to explain.
Why does this matter? If you ever plan on designing a customer survey or doing cursory exploratory data analysis, you’ll benefit from understanding basic data types.
That’s the academic stance, but in a more pragmatic stance, analytics tools (including programming languages like R and Python and tools like Excel) also have distinct data types, and these matter for both formatting and analysis.
For example, R has 6 main data types:
- character: “a”, “swc”
- numeric: 2, 15.5
- integer: 2L (the L tells R to store this as an integer)
- logical: TRUE, FALSE
- complex: 1+4i (complex numbers with real and imaginary parts)
If you don’t understand data types, you’ll get a lot of “error” messages when you start coding.
3. Utility vs. Precision Tradeoff
Data analysis is a method by which we attempt to reduce uncertainty, and uncertainty can never be completely eliminated.
Therefore, there comes a point of diminishing marginal utility with increased precision of the model.
In other words, the more data you collect or the more accurate the data matters up to a certain point, and beyond that, the value of increased data or increased accuracy matters very little but the cost of collecting the data or increasing the precision becomes very high.
For example, an A/B test is the gold standard of causal inference, but you can never be completely 100% confident that a variant is truly better than the original.
That’s why we use inferential statistics (and why you should grok what a P Value means).
Running an A/B test for 2-4 weeks and with a P Value threshold of <.05 tends to be an acceptable value of uncertainty vs the hyperbolic flip side of just running an experiment for eternity (which costs you in “regret” — the value you missed out on by not exploiting the optimal variant more quickly).
There’s a point at which “more data” is not only not beneficial, but may harm you.

4. Bias vs. Variance
This is a cool concept from Machine Learning, very related to the modeling trade-off above between the overly simple and the overly precise.
This is from TowardsDataScience:
“What is bias?
Bias is the difference between the average prediction of our model and the correct value which we are trying to predict. Model with high bias pays very little attention to the training data and oversimplifies the model. It always leads to high error on training and test data.
What is variance?
Variance is the variability of model prediction for a given data point or a value which tells us spread of our data. Model with high variance pays a lot of attention to training data and does not generalize on the data which it hasn’t seen before. As a result, such models perform very well on training data but has high error rates on test data.”
There’s always a trade-off, no perfect model (“all models are wrong; some are useful”). One favors simplicity and has a high rate of Type I errors, the other overcomplicates things as misses things it should include (Type II errors)

5. Signal vs. Noise
Personally, I believe most data we look at is actually noise.
While humans constantly seek patterns and explanations, I think more of what we see can be described by randomness than we’d imagine. Whether regression to the mean, seasonality (misunderstood and over-invoked, by the way), Type I (or Type II) errors, or just a tracking error, a lot of what looks peculiar (especially when we’re seeking and incentivized to seek peculiar “insights”) is just noise.
Your goal is to find the signal, data that helps inform action and better decision making.
This is easier in some contexts than others.
For example, running a controlled experiment on a landing page with only paid acquisition traffic is a highly controlled environment, and you can use tools like statistical significance, statistical power, and confidence intervals to infer whether or not what you’re seeing is signal or noise.
Tracking time-series variables across a website and with little experience parsing out seasonality and random factors, you’re constantly at the whim of noise. This leads you to see patterns where they may not exist, and at the worst case, that leads you to take actions or make decisions based on illusions.

How much variance is expected in the data environment you’re working in? Does this observation fall outside of the expected margin of error? If so, how can we explain it, and if possible, can we run experiments to counter-intuit our way to a future action?
(Side note: noise and the storytelling that follows it is why I generally hate the use of things like click and scroll heat maps in decision making, as well as overly frequent causal analyses on time series or extrapolating too much meaning on tiny segments of users).
6. Correlation vs. Causation
This is elementary stuff. Just because one thing happens while another thing happens doesn’t mean they’re related (though it also doesn’t mean they’re not related — sorry to confuse things, let’s move on).
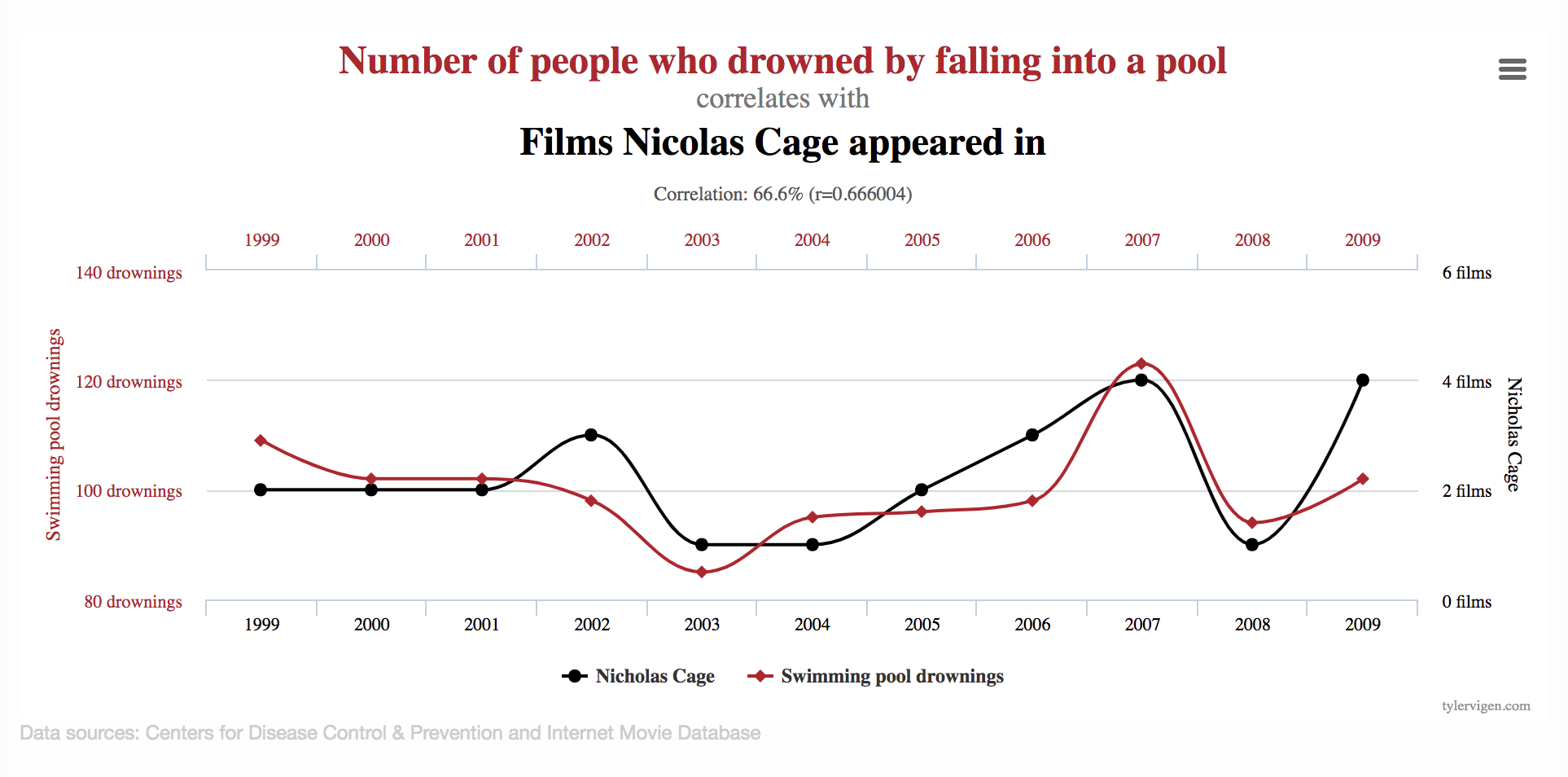
The more you look for correlations, the more they appear. That’s why “Swimming in the Data” is such a tragedy, and you need to ask clear business questions.
This is actually a much deeper topic than it appears on the surface, though in your average business role you probably don’t need to dive down the causality rabbit hole, as it gets quite philosophical (seeking answers to the epistemological question, “how does one truly know anything?”).
If you do want to go down that rabbit hole, The Book of Why by Judea Pearl is a cool non-technical book on the subject. But you may also wind up reading Hume and Popper and whatnot too (don’t blame me if you fall down that rabbit hole).
7. Correlation vs. Correlation
I’d even be careful with correlation in many cases. While they can be great starting points for further business questions and probing, they can be horrible as conclusions, and in summary statistics, they can often mislead.
See Anscombe’s quartet:
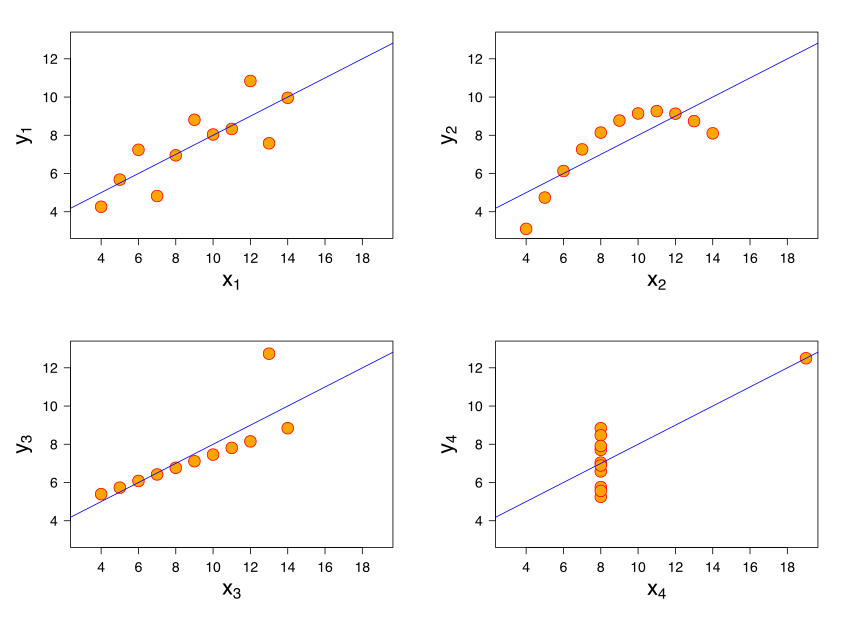
It’s important to understand concepts like variance and outliers.
8. Narrative Fallacies and Common Biases
Cognitive biases are the subject of many great books. Some of my favorites include:
- Incerto by Nassim Taleb
- Thinking Fast and Slow by Daniel Kahneman
- The Halo Effect by Phil Rosenzweig
Say what you will about “rationality” (I find it overrated in many cases), humans are prone to fooling themselves, especially our world of increasingly big data.
There’s no way you’ll ever stop fooling yourself (this is called “bias blind spot”), but knowing a few common fallacies and biases that have to do with data will help prevent you from at least some percentage of misreading and mistakes.
- Narrative fallacy (really a series of fallacies that have to do with connecting disparate and unrelated dots in attempt to form a cohesive pattern or narrative)
- Hindsight bias (overestimating your ability to have predicted an outcome that could not possibly have been predicted. “I knew it!”)
- Texas Sharpshooter Fallacy (repainting the target after the data points have accumulated to make random data points appear causal and clustered/related. Also known as clustering illusion or cherrypicking.)
I find these biases and fallacies endlessly fascinating. No matter what, we’ll all still fall into them from time to time, but learning about them can help mitigate that and can help you see it when it happens in your organization.
9. Twyman’s Law
Twyman’s law states that “Any figure that looks interesting or different is usually wrong.”
So if you see an A/B test with a reporting 143%+ lift, I’d ask questions. What was the sample size? Segment? How long did the test run? Peaking at the data/p-hacking?
Not saying all surprising data is wrong, but it’s often the case that it is.
In short, skepticism and critical thinking is your best friend when it comes to data.
As my friend Mercer says, “trust, but verify.”
10. Leaky Abstractions in Analytics Tools
The platform you’re using for data has abstracted away some level of the underlying function of the tool. That’s why you bought the platform — so you don’t have to develop everything from scratch.
However, with that abstraction comes a loss in comprehension of necessary components of the system. In a great paper by Lukas Vermeer of Booking.com, he explains that experimentation platforms abstract away such aspects of experimental design as:
- statistical units and tracking (how do you determine a unit of observation and log it)
- sampling (how do you randomize and sample from your population)
- definition and implementation of metrics (how are metrics grouped and defined)
- business meaning of metrics
Yet, “the experimenter needs to be well-informed of their intricacies in order to base a sensible decision on the collected data.”
In short, using tools helps democratize data, but you still need experts with understanding of the underlying structure of the system.
If you use Google Analytics, you need someone on your team to understand how the system works and the data is structured.
You should understand how your A/B testing tool randomized users, logs units of observation, defines metrics, and performs statistical inference.
In short, there’s no shortcut. Skip the deep understanding of your tools and you’re liable to misunderstand the data they provide, which could lead you to worse outcomes or spending a ton of time and money fixing them (which defeats the utility of data in the first place!)
Conclusion (and Further Data Literacy Resources)
Data literacy is a strange term. In fact, I actually didn’t know it was a term until I started doing keyword research after I had already written this article. After learning that it basically means “knowing how to understand and interpret data,” I figure it was a good fit for this article. However, there’s no end point to data intelligence. It’s a constant journey where the more you learn, the more you realize you still don’t know.
In any case, I want to leave you with some of my favorite resources for learning more about data:
- CXL Institute – awesome courses on CRO, analytics, databases, etc.
- Udacity – Nanodegree programs on everything from machine learning to digital analytics and more.
- How Not to be Wrong – book on interesting mathematical concepts
- The Drunkard’s Walk – a book all about probability and randomness
- Incerto – Nassim Taleb’s multi-volume book collection on probability, risk, etc.
- A/B testing books – a list of my favorite books about A/B testing
- CRO books – a list of my favorite books about CRO
- 5 Questions to Ask When Approaching Digital Analytics – an article I wrote for CXL on good skeptical questions to ask of your data.
- How to Avoid Being Deceived By Data – article I wrote for CXL on how to lie with statistics (and avoid being deceived)